Back to Main Page
How the SparcElectric Test-bed was Generated
See the latest Updates
Technical and Entity Information
Overview:
This is a preliminary setup of data for a mixed workload data warehouse combining OLTP properties with data warehouse capabilities. The generated portions follow the fleet operations for the company, mainly work orders, on both customer accounts and the company’s electric infrastructure. Additional pieces will be added in future, such as meters and grid storage, as well as adjustments to the balance of the fleet work order numbers.
Customer and Inventory tables serve as base tables, and also as dimension tables. Several smaller supporting tables do the same. The tables WOCustomer and WOInfras are work order tables and hold from 1 ==> N multiple transactions against a single Spark work order (SparcWONumber).
The tables WorkOrderCustFact, WorkOrderInfrasFact, and DimDate are all data warehouse tables, and serve to prepare and aggregate information about customer work orders, and infrastructure/inventory work orders. DimDate holds multiple levels of date information for analysis to slice against.
Main Entities for the data mart focused on fleet operations:
Customer Entity and related tables, showing their relationships:
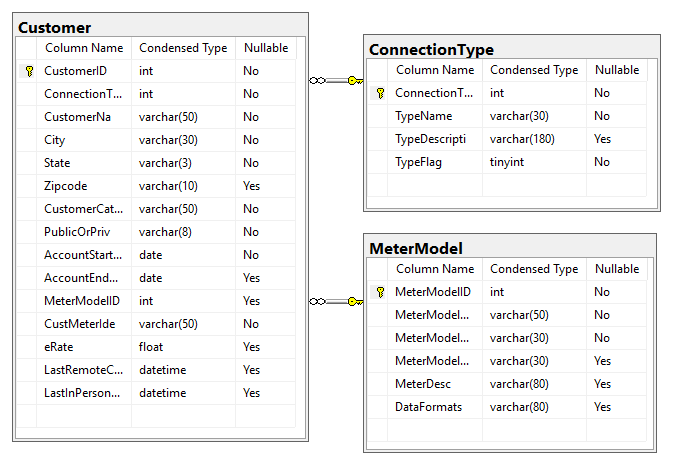
Customer’s relationships with other base tables
Inventory Entity and related tables, showing their relationships:
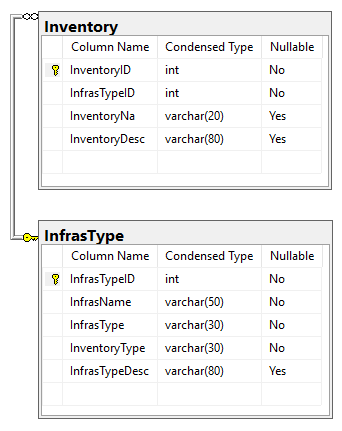
Inventory’s relationships with the infrastructure base tables
Employee Entity and related tables, showing their relationships:
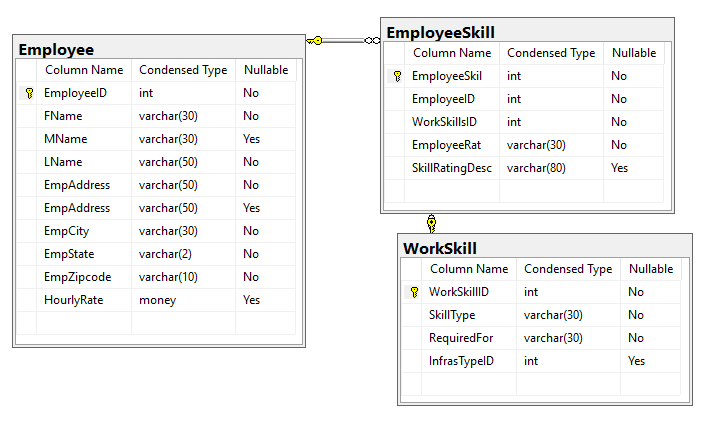
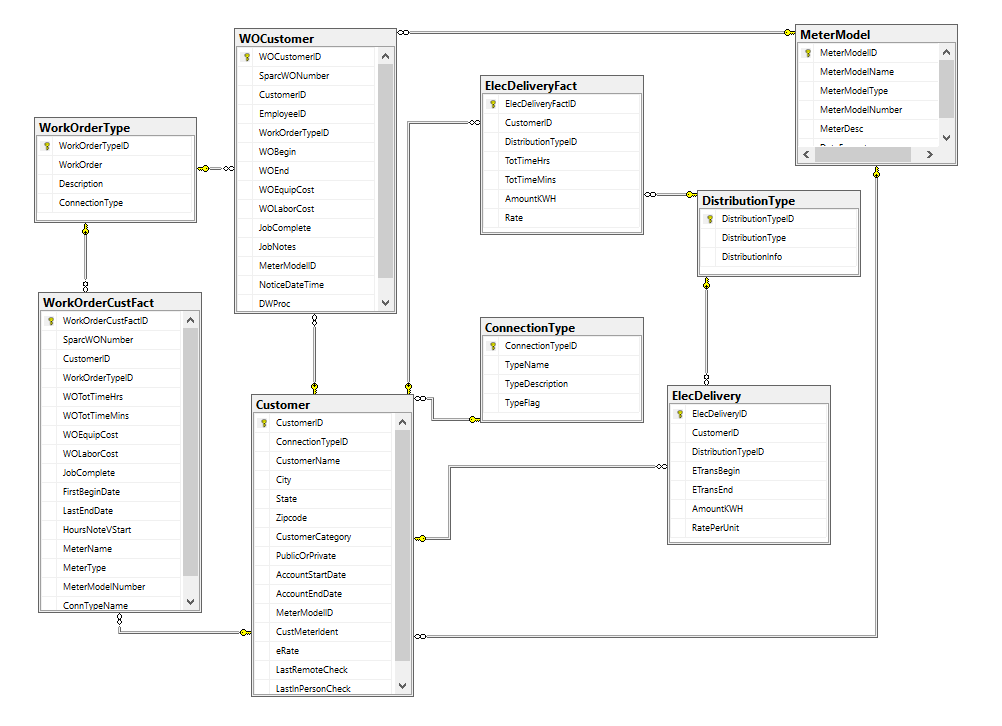
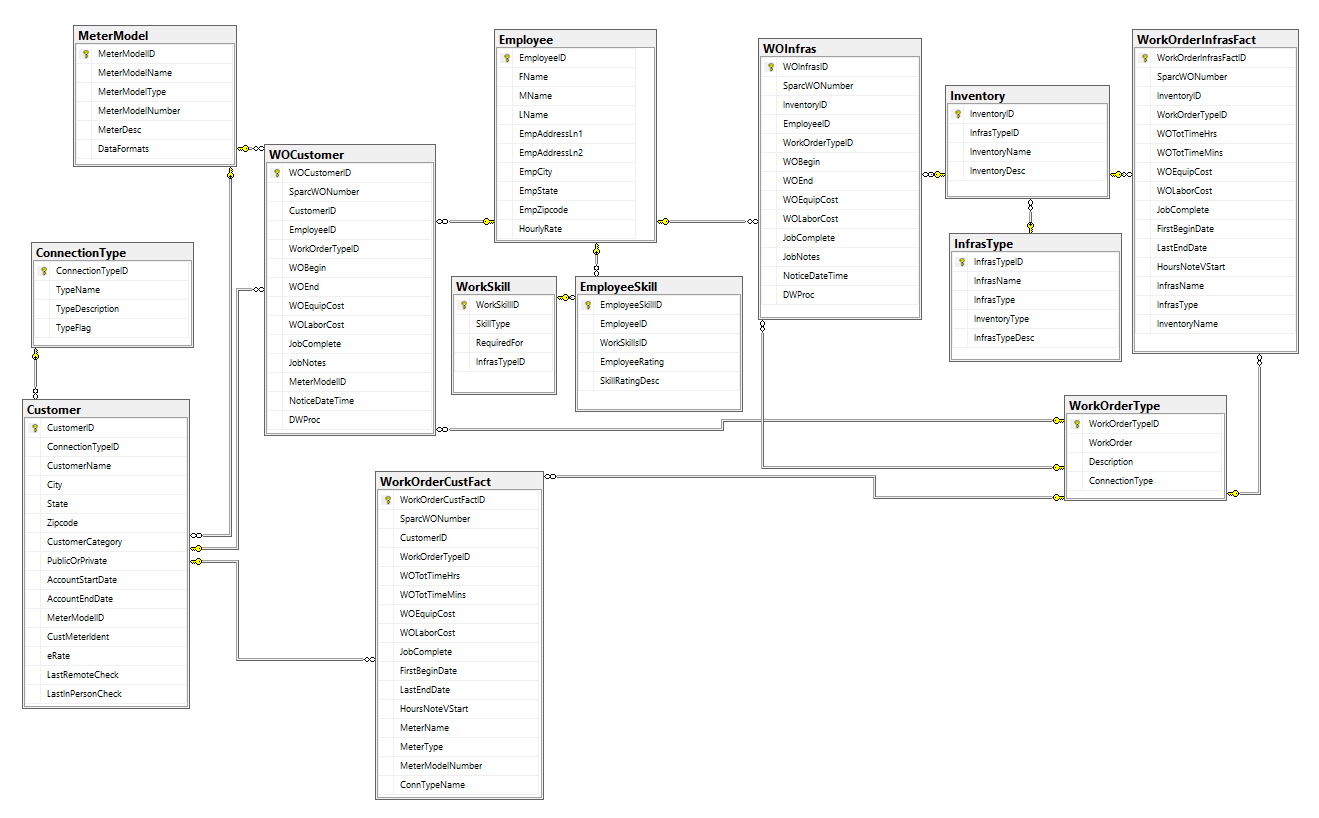
Work Order and related tables, showing their relationships: (a work order represents a service incident generated against either a customer account or an infrastructure / inventory element)

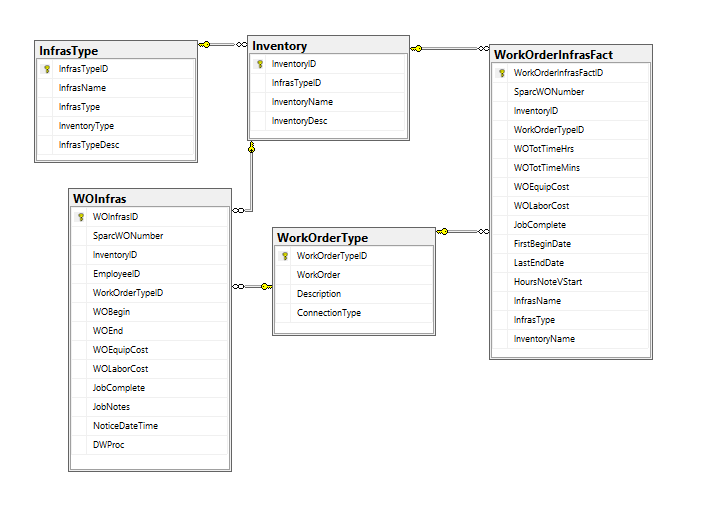
Complete Work Order tables
Test-bed Future Directions and Updates
- Testing of different query execution plans and adjustment of indexes (and the columns participating in them) where necessary. (Taking the time to check indexing for queries, instead of our single columns FKs).
- Before customer expansion and before the addition of meter reading, SparcElectric will need to consider how to handle partitioning (&filegroups).
- In conjunction with partitioning, SparcElectric will need to weigh the benefits and any drawbacks of implementing columnstore indexes on the largest tables in its non-standard implementation.
- Implement the Electric Delivery (Metering) data simulation. Add simulated near real-time meter reads, as SparcElectric migrates from its existing analog and AMR meters to fully digital and near-real-time data collection.
- Implement the Grid Storage data simulation. Add the entities and simulation of grid storage, interaction with outside vendors, and grid loss to the test-bed.
- Alter the methods of randomizing the data, to bring it more in line with what a real power company would experience.
- Move part or all of the simulation onto the Azure Platform. Migrate some (hybrid data environment) or all (total re-platforming).
“Lift and Shift” the SSIS packages that generate the simulated work orders onto Azure. (as an exercise to test the process.)- Rewrite ETL in Azure Data Factory instead of “Lift and Shift” for both financial reasons and to take advantage of new features.
- Add additional aggregation tables at larger granularity.
Back to Main Page
How the SparcElectric Test-bed was Generated
See the latest Updates